Key Takeaways
- ✓Machine learning terminology spans AI fundamentals, data concepts, technical roles, model-building techniques, and applied use cases.
- ✓Core concepts include artificial intelligence, machine learning, machine learning algorithms, machine learning models, big data, raw data, and structured or unstructured data.
- ✓Common methods include data mining, unsupervised learning, supervised learning, reinforcement learning, deep learning, neural networks, and generative adversarial networks.
- ✓Important use-case areas include natural language processing, computer vision, robotic process automation, and the internet of things.
- ✓A shared vocabulary can make it easier to compare machine learning programs, read job descriptions, and explore AI career paths.
Whether you’re researching bachelor’s or master’s machine learning programs, reading the news, or trying to parse job postings, you’re liable to encounter a host of terms that might not be immediately recognizable. To make your life easier, we’ve assembled this list of machine learning terms for your reference.
If you want more context after reviewing the glossary, AIFwD also covers AI vs machine learning vs deep learning, machine learning applications, machine learning in medicine, machine learning careers, and machine learning bootcamps.
“Understanding machine learning terms is a practical first step toward comparing programs, reading job posts, and building AI fluency.”— AIFwD Editorial Staff
Fundamentals
Artificial intelligence
Though the definition of artificial intelligence continues to be debated among experts, artificial intelligence can broadly be said to be the capacity of computers and other machines to think and act rationally in a given situation. An “AI” is also the name given to a computer or a machine that has this capacity. Today, however, AI engineers are increasingly attempting to endow AIs with human-like abilities beyond mere logical reasoning such as creativity and empathy.
Beyond this definition, however, a useful distinction often made is between “strong” AI or artificial general intelligence (AGI) and “weak” or “narrow” AI. AGI refers to yet-unrealized AI systems with human-like, or even super-human, intelligence, potentially even with self-consciousness, while narrow AI refers to the kinds of task-based AI technologies ubiquitous today.
Machine learning
A subset of artificial intelligence, machine learning focuses on the development of mathematical algorithms that allow computers to progressively improve their capabilities — “learning” as they go.
Machine learning algorithm
A machine learning algorithm is a bit of computer code written to process input data and arrive at usable output data. When fed “training data,” relevant input data for which the output is already known, machine learning algorithms are capable of “learning,” the end result being a machine learning model that can be used to make predictions and complete other tasks when fed with real-world data.
Machine learning model
A machine learning model is a software program that can make predictions and complete other important tasks when fed input data. Machine learning engineers develop machine learning models by feeding ML algorithms with “training data,” relevant input data for which the output is already known.
Big data
Big data is the collective name given to the massive, unwieldy data sets increasingly being created by users on the internet, especially social media; Internet of Things (IoT) devices; and cameras, microphones, and other sensors deployed throughout our world. Because big data sets resist analysis using traditional data processing software, machine learning solutions are commonly developed to extract insights and other intelligence from them.
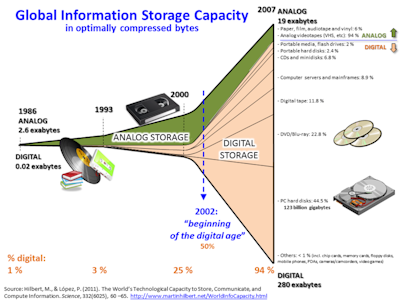
Raw data
Raw data refers to data that have not been processed, “cleaned,” or structured for analysis. Raw data is sometimes referred to as “primary data,” meaning data taken directly from its source.
Unstructured data
Unstructured data lack a predefined schema or model that would allow for easy grouping or classification of data points based on common parameters. Absent these parameters, analysts cannot meaningfully engage with a data set using traditional software like Excel or SQL.
Structured data
Structured data are highly organized with a specific format that allows them to be easily searched, manipulated, and analyzed using conventional methods according to specified parameters.
Professions & Adjacent Fields
Machine learning engineer
A machine learning engineer is responsible for end-to-end production of machine learning models — their design, development, and deployment — and for maintaining these models once they are shipped and deployed to a live product. Depending on where they work, machine learning engineers can also be responsible for managing data architecture and/or undertaking various kinds of data analysis.
Data science
According to IBM, data science is “a multidisciplinary approach to extracting actionable insights from the large and ever-increasing volumes of data collected and created by today’s organizations. [It] encompasses preparing data for analysis and processing, performing advanced data analysis, and presenting the results to reveal patterns and enable stakeholders to draw informed conclusions.”
Data scientist
A data scientist ideates and executes novel approaches that turn raw data into business insights and solutions. After understanding business needs, they determine what types of data are relevant in addressing those needs and what kinds of questions need to be asked of this data, and then help develop machine learning models and other predictive analytics to efficiently carry out this analysis. After the analysis, a data scientist is usually responsible for communicating results to relevant stakeholders.
Business analytics
Business analytics refers to the use of data analytics, data science, and machine learning to identify trends, diagnose problems, make predictions, and determine proper courses of action, all in service of maximizing business performance.
Techniques
Data mining
Data mining is the process of identifying patterns and other useful information in big data sets. Data mining can be descriptive, seeking merely to develop more knowledge about a given data set, or predictive, seeking to use a given data set to glimpse into what the future may hold. Machine learning is particularly useful for the latter case.
Unsupervised learning
Unsupervised machine learning refers to the use of unlabeled data sets to train a machine learning algorithm. Rather than learning by example, unsupervised ML algorithms are written to be able to make sense of the data themselves: discovering patterns and relationships, forming clusters, and cutting through the data to get to the most important data points.
Clustering
Clustering is a kind of unsupervised learning in which points from an unlabeled data set are sorted according to their similarities and differences. It is commonly used for tasks like market segmentation, online recommendation, search results, and medical imaging analysis.
Association
Association is a kind of unsupervised learning that searches big data sets or databases for interesting or useful relationships. These relationships are discovered by inputting a set of “if/then” rules into the algorithm, as well as a numerical criterion for how interesting, useful, or essential a found relationship might be. Association rule learning is commonly used for affinity or “market basket” analysis that looks for patterns in the kinds of products consumers buy. This kind of analysis is useful for everything from “Customers also Buy” product recommendation features to algorithm-generated music and video playlists.

Dimensionality reduction
Dimensionality reduction is a kind of unsupervised learning that simplifies data so that it can be more easily analyzed. In dimensionality reduction, a machine learning algorithm will analyze a large dataset and remove unnecessary or irrelevant parameters, or “dimensions.” Perhaps the most prominent example of a dimensionality reduction algorithm is the autoencoder, a type of neural network that learns to represent only the necessary elements of a dataset, without any so-called noise. A common use of autoencoders is in image or audio compression.
Supervised machine learning
Supervised machine learning refers to the use of labeled data sets — where each piece of data is tagged and classified — to train a machine learning algorithm to give the correct output when fed an input. Essentially, supervised machine learning helps algorithms build an ML model by learning by example. A common use of supervised learning is in email spam filters, where an algorithm is fed many examples of confirmed spam and gradually learns to identify it without prompting.
Within supervised machine learning, IBM identifies two common techniques, regression and classification. Both techniques are common for data mining, where big data sets are probed for interesting relationships, patterns, or outliers.
Regression
Regression is a kind of supervised learning that uses independent, known variables to predict the outcome of dependent variables. In linear regression, independent variables are used to predict the outcome of a single dependent variable. While there are countless applications for regression, one area where regression is proving particularly useful is in climate change research, where regression can be used to predict how the climate will react to certain changes.
Classification
Classification is a kind of supervised learning that focuses on sorting input data into various output groups. A common application is in spam filters. After being fed training data and instructed on which examples are “spam” or “not spam,” an algorithm learns to discern for itself which emails should land in your inbox and which should be siloed in your spam folder.
Reinforcement learning
Reinforcement learning is a machine learning technique in which ML algorithms are written to behave in ways that will maximize a numerical reward as they engage with a complex environment, usually through things called Markov decision processes. Reinforcement learning is applied throughout the industry, including in teaching cars how to drive themselves.
Deep learning
In deep learning, machine learning engineers deploy “artificial neural networks” (ANNs) of algorithms inspired by the synapses and neurons of the human brain and capable of performing complex analyses and tasks using big data sets. Key areas of use include natural language processing (NLP), computer vision, and robotic process automation (RPA). One notable application of deep learning came in the form of the AlphaGo program that was the first to defeat an expert Go player.
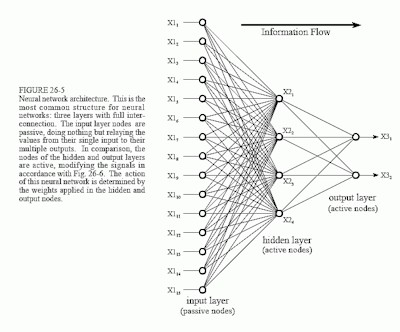
Neural network
A neural network comprises dozens of nodes (or more), each with an associated weight and threshold. As information passes through these nodes, these thresholds and weights determine whether the node allows information to pass through to the next node and, if so, how this information should impact the next layer of calculation and, ultimately, the neural network’s final output. Machine learning algorithms allow for these thresholds and weights to become more precise over time as the neural network learns.
Generative adversarial network
A generative adversarial network sets two neural networks — a generator and a discriminator — against each other in a zero-sum game in order to improve the network’s outputs. As the generator is trained to output examples of real-world data like photographs, the discriminator determines the quality or authenticity of these examples. This continues until the two neural networks reach a stasis, with the discriminator fooled by the generator half of the time.
Use Cases
Natural language processing
Borrowing from computer science, artificial intelligence, and linguistics, the subfield of natural language processing (NLP) centers on giving computers the ability to understand and use written and verbal language at a near-human level. An example of NLP that has received a lot of recent attention is OpenAI’s ChatGPT chat interface, newly open to the public.
Computer vision
Computer vision is an AI subfield with the goal of endowing computers with the ability to perceive, analyze, and act on visual stimuli as well as, or even better than, human vision. A current example, again from Apple, is the iPhone’s Face ID technology, though computer vision also has significant application in fields like healthcare and manufacturing.

Robotic process automation
Robotic process automation (RPA) is an AI subfield focused on the automation of complex business processes with the goal driving efficiency and productivity. By deploying metaphorical “software bots” rather than actual robots, companies are able to complete repetitive actions like bank transactions autonomously and at scale.
Internet of things
The term internet of things (IoT) refers to the wearables, smart security systems, and many other interconnected sensors that are becoming ubiquitous today. Machine learning plays a prominent role in the analysis of IoT data because the amount of data produced by these objects is so vast.
What next?
If you’re looking to dive further into machine learning — how it’s being used currently, what’s in store for its future, and how you can get involved — start with AIFwD’s guides to machine learning in business, machine learning in medicine and healthcare, machine learning applications, the future of machine learning, machine learning careers, machine learning bootcamps, machine learning books, and online machine learning courses.
Frequently Asked Questions
What are the most important machine learning terms to know first?+
Start with artificial intelligence, machine learning, machine learning algorithm, machine learning model, training data, big data, supervised learning, unsupervised learning, reinforcement learning, deep learning, and neural network.
What is the difference between AI and machine learning?+
Artificial intelligence is the broader field of building systems that can perform tasks associated with intelligence. Machine learning is a subset of AI focused on algorithms and models that improve through data.
What machine learning techniques should beginners understand?+
Beginners should understand supervised learning, unsupervised learning, reinforcement learning, regression, classification, clustering, association, dimensionality reduction, deep learning, and neural networks.
Why is machine learning vocabulary important?+
Machine learning vocabulary helps readers understand program descriptions, job postings, technical articles, product claims, and the differences between data science, AI engineering, and machine learning engineering roles.
Conclusion & Next Steps
Machine learning vocabulary can feel dense at first, but the core terms become easier to understand once you group them into fundamentals, professions, techniques, and use cases.
Use this glossary as a reference while comparing programs, reading technical explainers, and deciding which machine learning skills or career paths you want to explore next.
You Might Also Like
More education guides from our team